Learning Depth from Monocular Videos using Direct Methods
Abstract
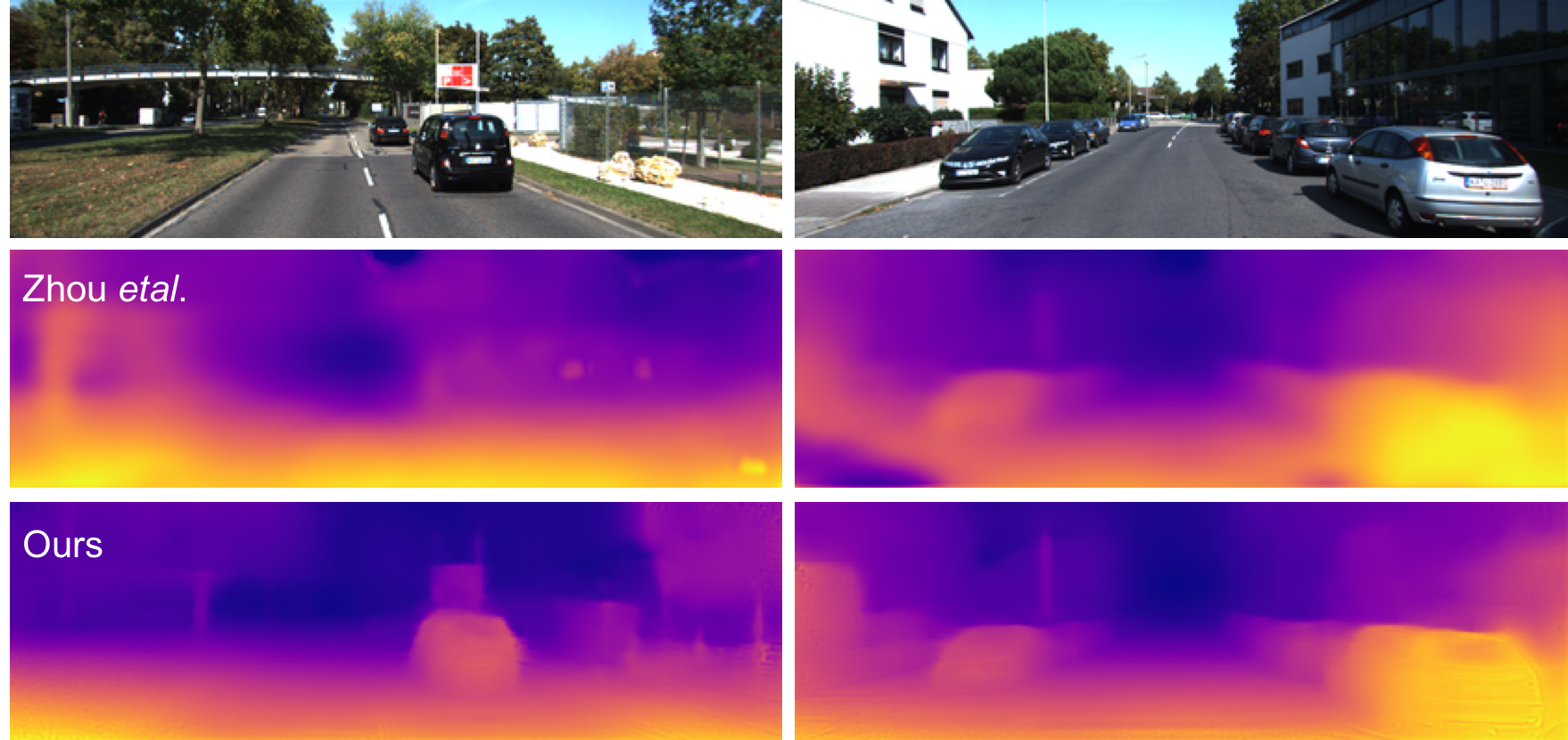
The ability to predict depth from a single image - using recent advances in CNNs - is of increasing interest to the vision community. Unsupervised strategies to learning are particularly appealing as they can utilize much larger and varied monocular video datasets during learning without the need for ground truth depth or stereo. In previous works, separate pose and depth CNN predictors had to be determined such that their joint outputs minimized the photometric error. Inspired by recent advances in direct visual odometry (DVO), we argue that the depth CNN predictor can be learned without a pose CNN predictor. Further, we demonstrate empirically that incorporation of a differentiable implementation of DVO, along with a novel depth normalization strategy - substantially improves performance over state of the art that use monocular videos for training.
 To be arXived.
To be arXived.